就去色 改造科学的10种磋磨机器具,你用过哪个?
发布日期:2024-12-17 22:08 点击次数:119

从Fortran到arXiv.org,从生物学的BLAST到东说念主工智能的AlexNet就去色,这些手艺逾越改造了科学,也改造了宇宙。
2019年,事件视界千里镜(EHT)拍摄了东说念主类第一张黑洞像片。这张有着亮堂光环的图像并非一张普通像片,而是由射电千里镜捕捉的数据通过算法合成的,联系的编程代码也在随后公布。用磋磨机编程来合成图像仍是成为一种越来越大宗的模式。
从天文体到生物学,当代科学的每一项要紧发现背后,王人有一台磋磨机。关联词,磋磨机并不成取代东说念主类的想考。如若莫得能够处理科知识题的软件,以及知说念怎样编写和使用软件的盘考东说念主员,哪怕是最苍劲的磋磨机也会毋庸武之地。今天,这些强力的软件仍是浸透到科研职责的各个方面。
《当然》杂志选出了对科学界产生要紧影响的10种软件器具。哪一款,你曾经经或正在使用?
1
编程谈话前驱:Fortran 编译器(1957)
第一台当代磋磨机并谢绝易操作。那时,编程果然是要手动“编”成的,盘考东说念主员需要用电线将成排电路鸠合起来。其后跟着机器谈话和汇编谈话的出现,用户才得以使用代码编写磋磨机技艺,但前提是需要对磋磨机架构有长远了解,这对许多科学家来说是可望不可即了。
到了上世纪50年代,跟着象征谈话冷静发展,这种情况驱动发生变化。尤其是 IBM 公司的工程师 John Backus 开拓的“公式翻译”谈话 Fortran 出现了。有了 Fortran 谈话,用户不错使用东说念主们可读懂的提示(如x=3+5),来编写磋磨机技艺。编译器会将这些提示调换成快速高效的机器代码。
1963年拜托给好意思国国度大气盘选取心的这台 CDC 3600 型磋磨机使用 Fortran 谈话编程。
不外,即使在发明 Fortran 以后,编程仍然不是一件容易的事。那时还莫得键盘与屏幕,技艺员必须将代码纪录在打孔卡上,一个复杂的模拟可能需要数万张打孔卡。即便如斯,Fortran 仍然让编程变得不再那么猴年马月,许多非磋磨机专科的科学家能够我方编写代码,处理所在领域的科知识题。
如今,Fortran 仍是走过了60多个岁首,仍然平方利用于征象建模、流体能源学、磋磨化学等诸多领域。由于运行迅速、占用内存小等优点,在职何波及到复杂的线性代数,且需要苍劲的磋磨机来快速处理数字的学科,王人不错看到 Fortran 的踪影,那些陈腐的代码仍活跃谢宇宙各地的实验室和超等磋磨机上。
2
信号处理器:快速傅立叶变换(1965)
当射电天文体家查察天外时,他们会捕捉到随时辰变化的复杂信号。为了确认这些射电波的本体,他们需要看到信号动作频率的函数是怎样变化的。傅里叶变换就不错将信号从时辰的函数调换为频率的函数。问题是,傅里叶变换不够高效,对于大小为N的数据集,需要N2次运算。
1965年,好意思国数学家James Cooley和John Tukey想出快速傅里叶变换(FFT)的门径来加快这个过程。FFT 使用递归这种“分而治之”的计谋,让一个函数反复调用本人,从而将磋磨傅里叶变换的问题简化到N log2(N) 步。N越大,速率提高越明显。对于1000个数据,速率进步大要是100倍;对100万个数据,速率进步大要则不错达到5万倍。
默奇森宽场阵列(Murchison Widefield Array)是位于澳大利亚西部的射电千里镜,使用快速傅里叶变换来处理数据。
事实上,德国数学家高斯在1805年就发明了FFT ,仅仅从未发表过。Cooley 和 Tukey 再行发现了这一门径,并开启了 FFT 在数字信号处理、图像分析、结构生物学等领域的利用。在许多东说念主看来,这是利用数学和工程领域中最伟大的发明之一。
好意思国劳伦斯伯克利国度实验室的 Paul Adams 回忆说,他在1995年领会细菌卵白质 GroEL 的结构时,即使使用 FFT 和超等磋磨机,磋磨过程如故消耗了数天时辰,“如若莫得 FFT,很难想象需要多万古辰才气作念出来。”
3
分子编目:生物数据库(1965)
西西人体艺术摄影今天,数据库仍是成为科学盘选取不可或缺的部分,以至于东说念主们很容易忽略一个事实——数据库是由软件驱动的。在昔日几十年中,数据库的范围急剧扩张,影响波及诸多领域,但惟恐莫得哪个领域的变化像生物学那样大。
如今雄伟的基因组和卵白质数据库发源于生物信息学前驱玛格丽特·戴霍夫(Margaret Dayhoff)的职责。上世纪60年代初,高洁生物学家们勉力于梳理卵白质的氨基酸序列时,戴霍夫驱动整理这些信息,从中寻找不同物种间演化关系的陈迹。1966年,她与妥洽者发表论文《卵白质序列与结构图谱》(Atlas of Protein Sequence and Structure),描画那时已知的65种卵白质的序列、结构和相似性,并将数据编目成打孔卡,使得检索和扩展数据库成为可能。
数字化的生物数据库(Biological database)紧随其后出现了。1971年,卵白质数据库(PDB)参加使用,如今它详确纪录了杰出17万个大分子结构。1982年,好意思国国度卫生盘考院(NIH)发布基因银行(GenBank)数据库,为DNA过火编码的卵白质成立档案。
这些资源很快就表露出了价值。1983年,两个孤立的团队王人精明到,东说念主体内一种特定的滋长因子与导致山公患癌的病毒卵白质在序列上相配相似。这个发现揭示出,一种病毒致癌的机制是通过师法滋长因子,率领细胞不受抵制地滋长。
因为这个发现,许多蓝本对磋磨机和统计学不感好奇羡慕的生物学家短暂咫尺一亮,意志到不错通过序列比对来确认联系癌症的一些事情。盘考者也被启发:除了假想实验来考据特定的假定,还不错去挖掘那些洞开的数据库,从中找出东说念主们从未猜想的有计划。
当不同数据库关联到沿路时,这种力量还会急剧增长。举例,一种名为 Entrez 的调处搜寻引擎不错匡助盘考者在DNA、卵白质和文献之间目田穿行。
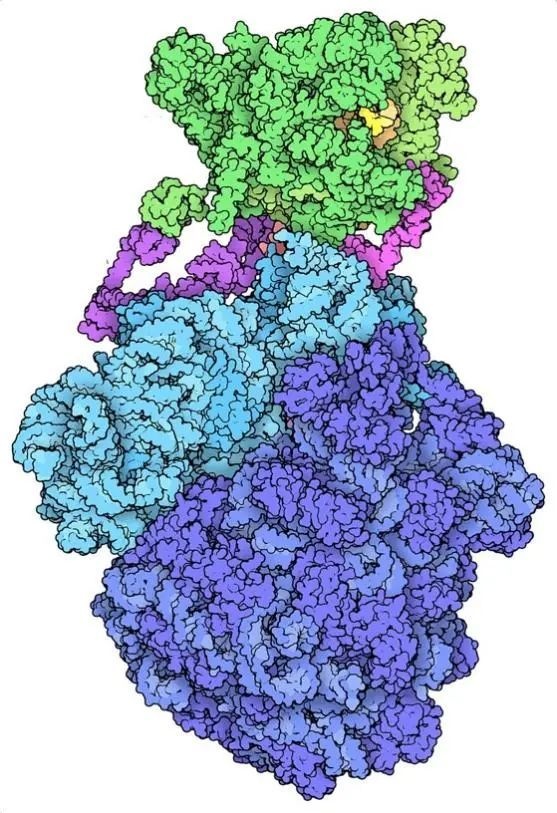
卵白质数据库领有杰出17万个分子结构的档案,包括图中的细菌抒发体(expressome)。|
4
情状预告:大气环流模子(1969)
第二次宇宙大战拆开时,磋磨机前驱冯·诺伊曼驱动将几年前用于磋磨弹说念轨迹和兵器假想的磋磨机转向天气展望问题。在此之前,东说念主们王人只可凭据警告和直观来作念天气预告,冯·诺伊曼的团队则试图通过基于物理学定律的数值磋磨来展望天气。
事实上,科学家在许多年前就熟知联系的数学方程式,但早期情状学家在处理实践问题时仍然无法可想,因为天气幻化莫测,远非数学家的磋磨才气比较!1922年,英国物理学家Lewis Fry Richardson最早发表了用数学模子展望天气的职责,要展望改日的天气,需要输入刻下的大气要求,磋磨它们在短时辰内会怎样变化,并不断访佛——这个过程相配耗时。他用几个月时辰才气展望改日几个小时的天气情况,何况很不靠谱,以至是“在职何已知陆地要求下王人不可能发生的展望”。
磋磨机的出现使这个数学利用确切变得可行。上世纪40年代末,冯·诺伊曼组建了一个天气预告团队,1955年,第二个团队——地球物理流体能源学实验室(Geophysical Fluid Dynamics Laboratory,GFDL)也驱动进行征象建模,之后他们作念出首个告捷展望的大气环流模子(General circulation model,GCM)。到了1969年,他们告捷将大气和海洋模子联接起来。
那时GCM模子相对来说还很纰漏,只障翳了地球名义的六分之一,将其差异为500平方公里的方块,大气也只分红了9层。而今天的情状模子会将地球名义差异为25×25公里的正方形,将大气差异为几十个层级。尽管如斯,这个模子仍然创造了科学磋磨的里程碑,它第一次用磋磨机测试了二氧化碳含量飞腾对征象的影响。
5
科学磋磨的基础:BLAS (1979)
科学磋磨每每会波及到向量和矩阵这些相对圣洁的数学运算,但在上世纪70年代以前,并莫得一套大宗认同的磋磨器具来施行这些操作。因此,从事科学职责的技艺员需要花许多时辰来假想代码,只为作念基本的数学运算,而不是专注于全体的科知识题。
编程领域需要的是一个模范。1979年,这个模范出现了,它便是基础线性代数子技艺库(Basic Linear Algebra Subprograms),简称BLAS。BLAS 把矩阵和向量磋磨简化成加法、减法这么基本的磋磨单位。这个模范一直发展到1990年,界说了数十个向量和矩阵数学的基簿子技艺。
BLAS 无意是为科学磋磨而界说的最蹙迫的接口。它为常用函数提供了模范化称号;基于 BLAS 的代码在职何磋磨机上王人以相通的风物职责;此外,成立模范也使得磋磨机制造商不错优化 BLAS,收场在不同硬件上的快速运算。不错说,BLAS 为科学磋磨提供了基础。
在编程器具 BLAS 于1979年问世前,好意思国劳伦斯利弗莫尔国度实验室的超等磋磨机Cray-1上职责的盘考东说念主员,并莫得效于线性代数磋磨的模范。
6
显微镜必备:NIH Image(1987)
上世纪80年代初,好意思国国度卫生盘考院(NIH)脑成像实验室有一台扫描仪不错将 X 光片数字化,但无法在电脑上表露或分析这些图像。于是,在这里职责的技艺员 Wayne Rasband 便写了一个技艺来收场这个处所。
领先这个技艺是挑升为一台价值15万好意思元的 PDP-11磋磨机而假想,之后在1987年,苹果公司发布 Macintosh II,Rasband 又将软件移植到这个便于个东说念主使用的新平台上,成立了一个图像分析系统,也便是NIH Image。
NIH Image的后继者包括 ImageJ 和 Fiji,盘考东说念主员不错在职何磋磨机上检察和分析图像,已成为生物学家的基础器具,任何一个使用过显微镜的生物学家对它们王人不会生分。
ImageJ 提供一个看似圣洁的极简主见用户界面,自上世纪90年代以来简直莫得改造。关联词,这个器具实践上具有无尽的可扩展性——兼容平方的文献姿色,具有生动的插件架构,还有宏纪录器,不错通过纪录鼠标操作来保存职责经过。东说念主们假想了多样专有的插件,有的不错自动识别细胞,有的不错跟踪处所,用户不错很容易地按照我方的需求,使 ImageJ 器具更个性化。
在插件的匡助下,ImageJ 器具不错自动识别显微镜图像中的细胞核。
7
序列搜索:BLAST (1990)
说到搜索,咱们会说去Google一下;在遗传学中,科学家则会说去BLAST一下某个分子序列。从软件称号形成动词,大要是讲解使用平方性的最佳方针了。(编者注:对于东说念主名的动词化或形容词话,参见《厄米特:门道陡立的天才数学家丨贤说八说念》第5节)
进化带来的改造纪录在分子序列中,比如替代、缺失、重排等。通过搜寻分子序列,终点是卵白质的氨基酸序列之间的相似性,盘考东说念主员不错发现它们的演化关系,并长远了解基因的功能。不外,问题的重要是要在迅速扩张的分子信息数据库中,快速而全面地作念到这少量。
生物信息学前驱玛格丽特·戴霍夫(便是前文成立生物数据库原型那位)在1978年作出了重要性的孝顺。她假想了一种PAM矩阵,其各个格点上的数值为一种氨基酸被另一种氨基酸替换的概率。这使得盘考东说念主员在对两种卵白质的亲缘关系进行评分时,不仅不错依据其分子序列的相似进度,还不错依据它们之间的演化距离。
1985年,东说念主们进一步联接PAM矩阵和快速搜索才气,引入了一种叫作FASTP的算法。几年之后,功能更苍劲的BLAST出身,并于1990年发布。
BLAST不仅不错快速搜索日益雄伟的数据库,还不错找到那些在演化关系上距离更远处的匹配,并磋磨这些匹妃耦然发生的可能性有多大。它速率迅速且容易使用。对于那时处于萌芽阶段的基因组生物学而言,BLAST是一个变革性的器具,科学家不错凭据联系基因的功能,找出未知基因可能发扬什么作用。
8
预印本平台:arXiv.org(1991)
上世纪80年代末,高能物理学家频繁会将已递交的论文副本邮寄给同业征求见地,也出于一种礼仪,但这往往只局限于少数东说念主。处于“食品链”较低位置的科学家不得不依赖大牛们的股东,而许多雷同有抱负的盘考东说念主员,却每每因为他们并非来自顶尖机构而被摈斥在圈子除外。
1991年, 那时在洛斯阿拉莫斯国度实验室职责的物理学家 Paul Ginsparg 写了一封自动回应电子邮件,试图成立更公说念的竞争环境。订阅者不错收到逐日的预印本清单,每一个王人与著作象征符联系联。通过一封电子邮件,宇宙各地的用户就不错通过实验室的磋磨机系统,提交或检索一篇著作,获取新著作的列表,也不错按作家或标题进行搜索。
Ginsparg 的野心是将著作保留三个月,并将内容划定在高能物理领域。但一位共事劝服他无尽期保留这些著作。就在那一刻,它从通报栏形成了档案馆。论文簇拥而至,高能物理除外的其他领域也涌入进来。1993年,Ginsparg 将系统迁徙到万维网上, 在1998年给它取了目前的名字—— arXiv.org。
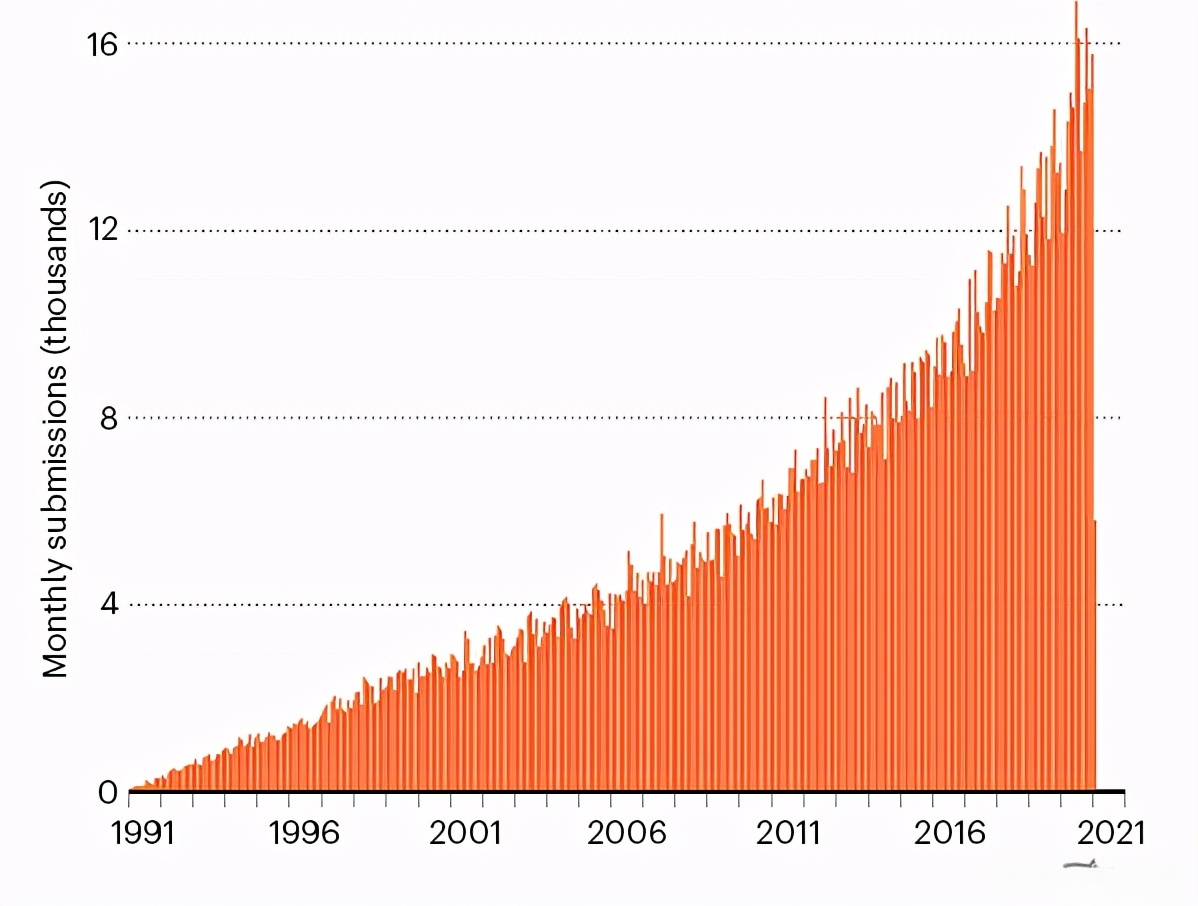
本年,arXiv 仍是成立30年,领有约180万份预印本,全部免费提供,每月眩惑杰出1.5万份提交和3000万次下载。它为盘考东说念主员提供了一种展示学术职责的快速圣洁的风物,从而幸免了传统的同业评议期刊所需的时辰和各样穷苦。
从1991年到2021年,arXiv每月眩惑提交的预印本数目捏续增长。
arXiv 的告捷催生了其他论文预印本网站的茂密,包括生物学、医学、社会学等诸多学科。今天,从已发表的数万份对于“新冠”病毒的预印本中,就不错看到它的影响。(编者注:参见《预印本论文靠谱吗?》)这个30年前在粒子物理学界除外被合计是异端的门径,如今早已被视为自关联词然的存在。
9
数据浏览器:IPython Notebook(2011)
Python是一种解释型谈话,技艺会将代码一瞥一瞥径直运行。技艺员不错使用一种被称为“读取-求值-输出轮回”(REPL)的交互式器具,在其中输入代码,然后由被称为解释器的技艺施行它。REPL允许快速探索和迭代,但 Python 的REPL 并不合适作念科学磋磨,举例,它不允许用户普通预加载代码模块,或洞开数据可视化。
于是在2001年,那时如故盘考生的 Fernando Pérez 写了我方的版块,这便是 IPython,一个交互式 Python 解释器,一共259行代码。十年后,IPython被迁徙到浏览器上,成为 IPython Notebook,并开启了一场数据科学翻新。
IPython Notebook 如实像札记本一样,将代码、拆开、图像和文本王人放在一个文档中。与其他类似面孔不同的是,它是开源的,接待所有开拓者孝顺一己之力。何况它撑捏 Python 这个广受科学家接待的编程谈话。2014年,IPython 演变为 Jupyter,撑捏大要100种谈话,允许用户圣洁地在辛勤超等磋磨机上探索数据。
对于数据科学家来说,Jupyter 实践上仍是成为一个模范。2018年,在 GitHub 代码分享平台上有250万个Jupyter札记本;今天则有近1000万个,包括 2016 年发现引力波和2019年拍摄黑洞第一张像片的代码。
10
快速学习者:AlexNet (2012)
东说念主工智能(AI)有两种类型:一种使用成文的章程,另一种通过模拟大脑的神经结构来让磋磨机“学习”。在很万古辰里,东说念主工智能盘考者王人合计,后一种类型的AI是行欠亨的。然则2012年,知名磋磨机科学家 Geoffrey Hinton 的两名盘考生 Alex Krizhevsky 和 Ilya Sutskever 讲解注解,事实并非如斯。
他们基于深度学习的神经蚁集算法假想了 AlexNet,参加2012年的 ImageNet 大范围视觉识别挑战赛。盘考者要用包含100万张日常物体图像的数据库来覆按 AI,然后用另一个孤立的图像集测试生成的AI算法,临了评估算法对图像作出正确分类的比率。那时最佳的算法会舛错地分类大要1/4的图像,AlexNet 基本上将舛错率简直减半,裁汰到了约16%。
AlexNet在2012年的告捷成绩于三个身分:裕如大的覆按数据集、出色的编程和 GPU 的苍劲功能,即使后者实践是为了进步磋磨机图形性能的。但盘考东说念主员依此将算法的运行速率提高了30倍。但这还不够,算法上的确切冲突实践上发生在三年前。那时 Hinton 实验室创建了一个神经蚁集,不错比经过数十年改良的传统AI更准确地识别语音。诚然仅仅略微逾越了少量,却标志着确切的手艺冲突。
这些后果预示了深度学习在各个领域的崛起。如今,咱们的手机能确认语音查询,生物学实验室中的图像分析器具能在显微像片中识别出细胞就去色,王人依赖于深度学习算法。AlexNet 也因此成为改造科学,也改造宇宙的器具之一。